
코딩테스트에서의 시간복잡도
데이터 크기에 따른 시간복잡도
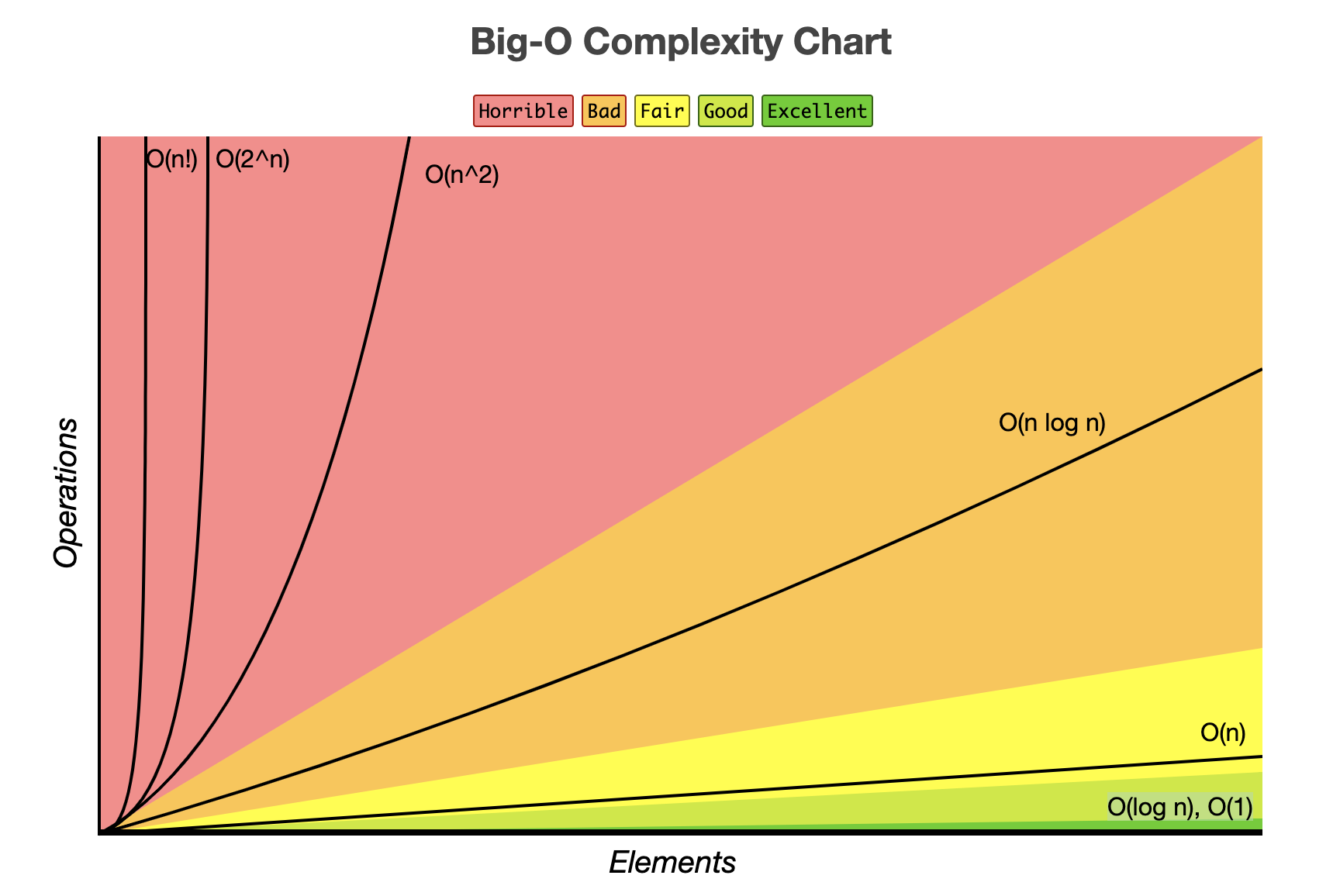
대략적인 기준입니다.
| 데이터 크기 제한 | 예상 시간복잡도 |
|---|---|
| n ≤ 1,000,000 | O(N) or O(logN) |
| n ≤ 10,000 | O(N^2) |
| n ≤ 500 | O(N^3) |
ex. 입력 데이터 크기가 최대 100,000이라면, O(n^2)보다는 작은 복잡도 O(NlogN) > O(N) > O(logN) > O(1) 를 고려해야 합니다.
자바스크립트 Array 메서드 시간복잡도
0. Array[i] - O(1)
인덱스로 배열 요소 찾기
function constantFromArr(arr, index) {
return arr[index];
}
Mutator Methods
1. push() - O(1)
배열 끝에 새 요소 추가 (기존 요소의 인덱스가 유지되기 때문에 constant time)
const names = ["Luis", "John", "Jose"];
names.push("Aaron");
console.log(names); // (4) ["Luis", "John", "Jose", "Aaron"]
2. pop() - O(1)
배열 끝의 요소 삭제 (기존 요소의 인덱스가 유지되기 때문에 constant time)
const names = ["Luis", "John", "Jose", "Aaron"];
console.log(names.pop()); //Aaron
console.log(names); // (3) ["Luis", "John", "Jose"]
3. unshift() - O(N)
배열의 첫 요소 추가 (기존 요소 인덱스 i -> i+1 이 됨, n번 재할당)
const names = ["Luis", "John", "Jose"];
console.log(names.unshift("Aaron")); // 4
console.log(names); // (4) ["Aaron", "Luis", "John", "Jose"]
4. shift() - O(N)
배열의 첫 요소 삭제 (기존 요소 인덱스 i -> i-1 이 됨, n번 재할당)
const names = ["Luis", "John", "Jose", "Aaron"];
console.log(names.shift()); // Luis
console.log(names); // (3) ["John", "Jose", "Aaron"]
5. splice() - O(N)
인덱스로 새 요소를 추가, 삭제, 대체 (i 이후 인덱스 j -> j+1 or j-1, n번 재할당)
const names = ["Luis", "John", "Jose", "Aaron"];
console.log(names.splice(0, 0, "Fernando")); // Add Michelle
console.log(names.splice(0, 1, "Michelle")); // replace Fernando to Michelle
console.log(names.splice(0, 1)); // remove Michelle
console.log(names); // (4) ['Luis', 'John', 'Jose', 'Aaron']
6. sort() - O(N logN)
인자값으로 넘어온 함수에 따라 값을 정렬. funtion이 없을 경우, Unicode 값으로 정렬. (Firefox에서는 merge sort, Chrome에서는 Timsort 방식을 사용합니다.)
const names = ["Luis", "Jose", "John", "Aaron"];
console.log(names.sort()); // (4) ["Aaron", "John", "Jose", "Luis"]
/*complex sorting*/
const users = [
{ name: "Luis", age: 25 },
{ name: "Jose", age: 20 },
{ name: "Aaron", age: 40 },
];
const compareFuc = (item1, item2) => {
return item1.age - item2.age;
};
console.log(users.sort(compareFuc));
/**
[{name: "Jose", age: 20}, {name: "Luis", age: 25}, {name: "Aaron", age:40}]
*/
Accessor Methods
1. concat() - O(N)
두 개 이상의 배열을 합쳐 새 배열 생성
const names1 = ["Luis", "Jose"];
const names2 = ["John", "Aaron"];
const newArray = names1.concat(names2, ["Michelle"]);
console.log(newArray); // (5) ["Luis", "Jose", "John", "Aaron", "Michelle"]
2. slice() - O(N)
배열의 시작과 끝 인덱스 사이의 배열을 복제하여 반환.
const users = [
{ name: "Luis", age: 15 },
{ name: "Jose", age: 18 },
{ name: "Aaron", age: 40 },
];
const adults = users.slice(1, users.length);
console.log(adults); // (2) [{name: "Jose", age: 18}, {name: "Aaron", age: 40}]
3. indexOf() - O(N)
배열의 원소가 존재하는 첫번째 인덱스를 반환. 원소가 배열에 없을 경우 -1을 반환.
const names = ["Luis", "Jose", "John", "Aaron"];
console.log(names.indexOf("John")); // 2
console.log(names.indexOf("Michelle")); // -1
Iteration Methods
1. forEach() - O(N)
배열의 각 요소에 함수 실행
const names = ["Luis", "Jose", "John", "Aaron"];
names.forEach((item) => {
console.log(item);
});
/* Print all user names
Luis Jose John Aaron
*/
2. map() - O(N)
배열 각 요소에 콜백함수를 실행한 결과값으로 새 배열 반환
const users = [
{ name: "Luis", age: 15 },
{ name: "Jose", age: 18 },
{ name: "Aaron", age: 40 },
];
const userDescriptions = users.map((item) => {
return `Hello my name is ${item.name} and I have ${item.age} years old.`;
});
console.log(userDescriptions);
/*["Hello my name is Luis and I have 15 years old.",
"Hello my name is Jose and I have 18 years old.",
"Hello my name is Aaron and I have 40 years old."] */
3. filter() - O(N)
주어진 조건에 참을 만족하는 요소만 가진 새 배열 반환
const users = [
{ name: "Luis", admin: true },
{ name: "Jose", admin: true },
{ name: "Aaron" },
];
const adminUsers = users.filter((item) => item.admin);
console.log(adminUsers); // [{name: "Luis", admin: true},{name: "Jose", admin: true}]
4. reduce() - O(N)
배열의 각 요소에 순서대로 reducer 함수 적용한 한 개의 결과값 반환
const users = [
{ name: "Luis", age: 15 },
{ name: "Jose", age: 18 },
{ name: "Aaron", age: 40 },
];
const reducer = (accumulator, item) => accumulator + item.age;
const totalAge = users.reduce(reducer, 0);
const ageAverage = totalAge / users.length;
console.log(`Total ${totalAge}, Average ${ageAverage}`); // Total 73, Average 24.333333333333332
Bonus!!!
1. some() - O(N)
주어진 조건에 맞는 원소가 1개 이상일 경우 true 반환. 조건에 맞는 원소가 없거나 빈 배열일 경우 false 반환.
const users = [
{ name: "Luis", admin: true },
{ name: "Jose" },
{ name: "Aaron" },
];
const adminExists = users.some((item) => item.admin);
console.log(adminExists); // true
2. every() - O(N)
주어진 조건에 모든 원소가 참일 경우에만 true 반환. 1개라도 조건에 맞지 않을 경우 false 반환.
const users = [
{ name: "Luis", active: true },
{ name: "Jose", active: true },
{ name: "Aaron", active: false },
];
const isAllUsersActive = users.every((item) => item.active);
console.log(isAllUsersActive); // false